🎱 GPT2 For Text Classification using Hugging Face 🤗 Transformers
Complete tutorial on how to use GPT2 for text classification!




Disclaimer: The format of this tutorial notebook is very similar to my other tutorial notebooks. This is done intentionally in order to keep readers familiar with my format.
This notebook is used to fine-tune GPT2 model for text classification using Huggingface transformers library on a custom dataset.
Hugging Face is very nice to us to include all the functionality needed for GPT2 to be used in classification tasks. Thank you Hugging Face!
I wasn’t able to find much information on how to use GPT2 for classification so I decided to make this tutorial using similar structure with other transformers models.
Main idea: Since GPT2 is a decoder transformer, the last token of the input sequence is used to make predictions about the next token that should follow the input. This means that the last token of the input sequence contains all the information needed in the prediction. With this in mind we can use that information to make a prediction in a classification task instead of generation task.
In other words, instead of using first token embedding to make prediction like we do in Bert, we will use the last token embedding to make prediction with GPT2.
Since we only cared about the first token in Bert, we were padding to the right. Now in GPT2 we are using the last token for prediction so we will need to pad on the left. Because of a nice upgrade to HuggingFace Transformers we are able to configure the GPT2 Tokenizer to do just that.
What should I know for this notebook?
Since I am using PyTorch to fine-tune our transformers models any knowledge on PyTorch is very useful.
Knowing a little bit about the transformers library helps too.
How to use this notebook?
Like with every project, I built this notebook with reusability in mind.
All changes will happen in the data processing part where you need to customize the PyTorch Dataset, Data Collator and DataLoader to fit your own data needs.
All parameters that can be changed are under the Imports section. Each parameter is nicely commented and structured to be as intuitive as possible.
Dataset
This notebook will cover pretraining transformers on a custom dataset. I will use the well known movies reviews positive — negative labeled Large Movie Review Dataset.
The description provided on the Stanford website:
This is a dataset for binary sentiment classification containing substantially more data than previous benchmark datasets. We provide a set of 25,000 highly polar movie reviews for training, and 25,000 for testing. There is additional unlabeled data for use as well. Raw text and already processed bag of words formats are provided. See the README file contained in the release for more details.
Why this dataset? I believe is an easy to understand and use dataset for classification. I think sentiment data is always fun to work with.
Coding
Now let’s do some coding! We will go through each coding cell in the notebook and describe what it does, what’s the code, and when is relevant — show the output.
I made this format to be easy to follow if you decide to run each code cell in your own python notebook.
When I learn from a tutorial I always try to replicate the results. I believe it’s easy to follow along if you have the code next to the explanations.
Downloads
Download the Large Movie Review Dataset and unzip it locally.
Installs
- transformers library needs to be installed to use all the awesome code from Hugging Face. To get the latest version I will install it straight from GitHub.
- ml_things library used for various machine learning related tasks. I created this library to reduce the amount of code I need to write for each machine learning project.
Installing build dependencies ... done Getting requirements to build wheel ... done Preparing wheel metadata ... done
|████████████████████████████████| 2.9MB 6.7MB/s
|████████████████████████████████| 890kB 48.9MB/s
|████████████████████████████████| 1.1MB 49.0MB/s
Building wheelfor transformers (PEP 517) ... done
Building wheel for sacremoses (setup.py) ... done
|████████████████████████████████| 71kB 5.2MB/s
Building wheel for ml-things (setup.py) ... done
Building wheel for ftfy (setup.py) ... doneImports
Import all needed libraries for this notebook.Declare parameters used for this notebook:
set_seed(123)- Always good to set a fixed seed for reproducibility.epochs- Number of training epochs (authors recommend between 2 and 4).batch_size- Number of batches - depending on the max sequence length and GPU memory. For 512 sequence length a batch of 10 USUALY works without cuda memory issues. For small sequence length can try batch of 32 or higher. max_length - Pad or truncate text sequences to a specific length. I will set it to 60 to speed up training.device- Look for gpu to use. Will use cpu by default if no gpu found.model_name_or_path- Name of transformers model - will use already pretrained model. Path of transformer model - will load your own model from local disk. In this tutorial I will usegpt2model.labels_ids- Dictionary of labels and their id - this will be used to convert string labels to numbers.n_labels- How many labels are we using in this dataset. This is used to decide size of classification head.
Helper Functions
I like to keep all Classes and functions that will be used in this notebook under this section to help maintain a clean look of the notebook:
MovieReviewsDataset(Dataset)
If you worked with PyTorch before, this is pretty standard. We need this class to read in our dataset, parse it and return texts with their associated labels.
In this class I only need to read in the content of each file, use fix_text to fix any Unicode problems and keep track of positive and negative sentiments.
I will append all texts and labels in lists.
There are three main parts of this PyTorch Dataset class:
- init() where we read in the dataset and transform text and labels into numbers.
- len() where we need to return the number of examples we read in. This is used when calling len(MovieReviewsDataset()).
- getitem() always takes as an input an int value that represents which example from our examples to return from our dataset. If a value of 3 is passed, we will return the example form our dataset at position 3.
Gpt2ClassificationCollator
I use this class to create the Data Collator. This will be used in the DataLoader to create the bathes of data that get fed to the model. I use the tokenizer and label encoder on each sequence to convert texts and labels to number.
Lucky for us, Hugging Face thought of everything and made the tokenizer do all the heavy lifting (split text into tokens, padding, truncating, encode text into numbers) and is very easy to use!
There are two main parts of this Data Collator class:
- init() where we initialize the tokenizer we plan to use, how to encode our labels and if we need to set the sequence length to a different value.
- call() used as function collator that takes as input a batch of data examples. It needs to return an object with the format that can be fed to our model. Luckily our tokenizer does that for us and returns a dictionary of variables ready to be fed to the model in this way:
model(**inputs). Since we are fine-tuning the model I also included the labels.
train(dataloader, optimizer_, scheduler_, device_)
I created this function to perform a full pass through the DataLoader object (the DataLoader object is created from our Dataset* type object using the **MovieReviewsDataset class). This is basically one epoch train through the entire dataset.
The dataloader is created from PyTorch DataLoader which takes the object created from MovieReviewsDataset class and puts each example in batches. This way we can feed our model batches of data!
The optimizer_ and scheduler_ are very common in PyTorch. They are required to update the parameters of our model and update our learning rate during training. There is a lot more than that but I won’t go into details. This can actually be a huge rabbit hole since A LOT happens behind these functions that we don’t need to worry. Thank you PyTorch!
In the process we keep track of the actual labels and the predicted labels along with the loss.
validation(dataloader, device_)
I implemented this function in a very similar way as train but without the parameters update, backward pass and gradient decent part. We don’t need to do all of those VERY computationally intensive tasks because we only care about our model’s predictions.
I use the DataLoader in a similar way as in train to get out batches to feed to our model.
In the process I keep track of the actual labels and the predicted labels along with the loss.
Load Model and Tokenizer
Loading the three essential parts of the pretrained GPT2 transformer: configuration, tokenizer and model.
For this example I will use gpt2 from HuggingFace pretrained transformers. You can use any variations of GP2 you want.
In creating the model_config I will mention the number of labels I need for my classification task. Since I only predict two sentiments: positive and negative I will only need two labels for num_labels.
Creating the tokenizer is pretty standard when using the Transformers library. After creating the tokenizer it is critical for this tutorial to set padding to the left tokenizer.padding_side = "left" and initialize the padding token to tokenizer.eos_token which is the GPT2's original end of sequence token. This is the most essential part of this tutorial since GPT2 uses the last token for prediction so we need to pad to the left.
HuggingFace already did most of the work for us and added a classification layer to the GPT2 model. In creating the model I used GPT2ForSequenceClassification. Since we have a custom padding token we need to initialize it for the model using model.config.pad_token_id. Finally we will need to move the model to the device we defined earlier.
Loading configuraiton...
Loading tokenizer...
Loading model...
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at gpt2 and are newly initialized: ['score.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Model loaded to `cuda`Dataset and Collator
This is where I create the PyTorch Dataset and Data Loader with Data Collator objects that will be used to feed data into our model.
This is where I use the MovieReviewsDataset class to create the PyTorch Dataset that will return texts and labels.
Since we need to input numbers to our model we need to convert the texts and labels to numbers. This is the purpose of a collator! It takes data outputted by the PyTorch Dataset and passed through the Data Collator function to output the sequence for our model.
I’m keeping the tokenizer away from the PyTorch Dataset to make the code cleaner and better structured. You can obviously use the tokenizer inside the PyTorch Dataset and output sequences that can be used straight into the model without using a Data Collator.
I strongly recommend to use a validation text file in order to determine how much training is needed in order to avoid overfitting. After you figure out what parameters yield the best results, the validation file can be incorporated in train and run a final train with the whole dataset.
The data collator is used to format the PyTorch Dataset outputs to match the inputs needed for GPT2.
Dealing with Train...
pos files: 100%|████████████████████████████████|12500/12500 [01:17<00:00, 161.19it/s]
neg files: 100%|████████████████████████████████|12500/12500 [01:05<00:00, 190.72it/s] Created `train_dataset` with 25000 examples!
Created `train_dataloader` with 782 batches!
Reading pos files...
pos files: 100%|████████████████████████████████|12500/12500 [00:54<00:00, 230.93it/s]
neg files: 100%|████████████████████████████████|12500/12500 [00:42<00:00, 291.07it/s]
Created `valid_dataset` with 25000 examples!
Created `eval_dataloader` with 782 batches!
Train
I created optimizer and scheduler use by PyTorch in training. I used most common parameters used by transformers models.
I looped through the number of defined epochs and call the train and validation functions.
I’m trying to output similar info after each epoch as Keras: train_loss: — val_loss: — train_acc: — valid_acc.
After training, plot train and validation loss and accuracy curves to check how the training went.
Note: The training plots might look a little weird: The validation accuracy starts higher than training accuracy and the validation loss starts lower than the training loss. Normally this will be the opposite. I assume the data split just happen to be easier for the validation part or too hard for training part or both. Since this tutorial is about using GPT2 for classification I will not worry about the results of the model too much.
Epoch
100%|████████████████████████████████|4/4 [15:11<00:00, 227.96s/it] Training on batches...
100%|████████████████████████████████|782/782 [02:42<00:00, 4.82it/s] Validation on batches...
100%|████████████████████████████████|782/782 [02:07<00:00, 6.13it/s]
train_loss: 0.54128 - val_loss: 0.38758 - train_acc: 0.75288 - valid_acc: 0.81904 Training on batches...
100%|████████████████████████████████|782/782 [02:36<00:00, 5.00it/s] Validation on batches...
100%|████████████████████████████████|782/782 [01:41<00:00, 7.68it/s] train_loss: 0.36716 - val_loss: 0.37620 - train_acc: 0.83288 -valid_acc: 0.82912 Training on batches...
100%|████████████████████████████████|782/782 [02:36<00:00, 5.00it/s] Validation on batches...
100%|████████████████████████████████|782/782 [01:24<00:00, 9.24it/s] train_loss: 0.31409 - val_loss: 0.39384 - train_acc: 0.86304 - valid_acc: 0.83044 Training on batches...
100%|████████████████████████████████|782/782 [02:36<00:00, 4.99it/s] Validation on batches...
100%|████████████████████████████████|782/782 [01:09<00:00, 11.29it/s] train_loss: 0.27358 - val_loss: 0.39798 - train_acc: 0.88432 - valid_acc: 0.83292
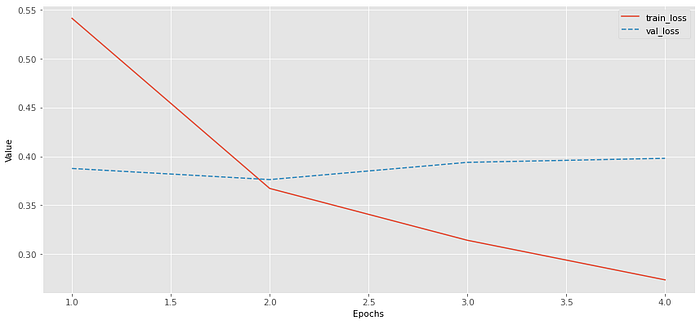
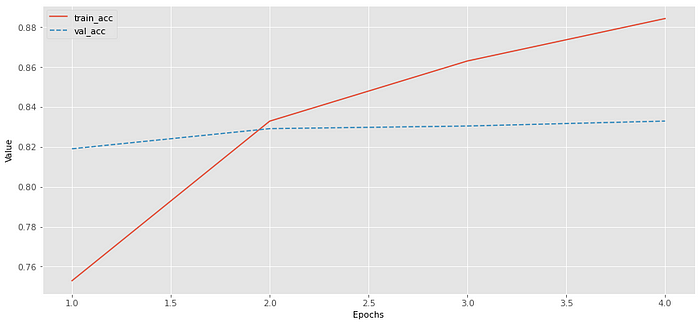
Evaluate
When dealing with classification is useful to look at precision recall and F1 score.
A good gauge to have when evaluating a model is the confusion matrix.
Training on batches...
100%|████████████████████████████████|782/782 [01:09<00:00, 11.24it/s]
precision recall f1-score support
neg 0.84 0.83 0.83 12500
pos 0.83 0.84 0.83 12500 accuracy 0.83 25000
macro avg 0.83 0.83 0.83 25000
weighted avg 0.83 0.83 0.83 25000
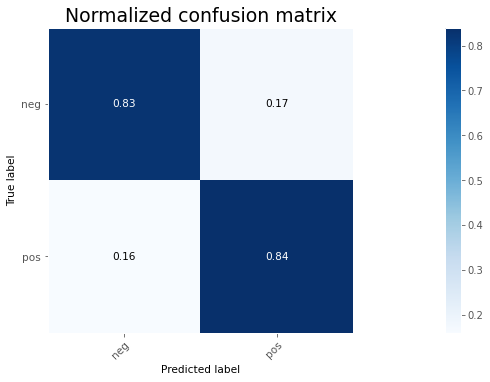
Final Note
If you made it this far Congrats! 🎊 and Thank you! 🙏 for your interest in my tutorial!
I’ve been using this code for a while now and I feel it got to a point where is nicely documented and easy to follow.
Of course is easy for me to follow because I built it. That is why any feedback is welcome and it helps me improve my future tutorials!
If you see something wrong please let me know by opening an issue on my ml_things GitHub repository!
A lot of tutorials out there are mostly a one-time thing and are not being maintained. I plan on keeping my tutorials up to date as much as I can.
Contact 🎣
🦊 GitHub: gmihaila
🌐 Website: gmihaila.github.io
👔 LinkedIn: mihailageorge
📓 Medium: @gmihaila
📬 Email: georgemihaila@my.unt.edu.com
Originally published at https://gmihaila.github.io.
