🐶 Pretrain Transformers Models in PyTorch using 🤗 Transformers
Pretrain or train from scratch 67 transformers models on your custom dataset.




Disclaimer: The format of this tutorial notebook is very similar with my other tutorial notebooks. This is done intentionally in order to keep readers familiar with my format.
This notebook is used to pretrain transformers models using Huggingface on your own custom dataset.
What do I mean by pretrain transformers? The definition of pretraining is to train in advance. That is exactly what I mean! Train a transformer model to use it as a pretrained transformers model which can be used to fine-tune it on a specific task!
I also use the term fine-tune where I mean to continue training a pretrained model on a custom dataset. I know it is confusing and I hope I’m not making it worse. At the end of the day you are training a transformer model that was previously trained or not!
With the AutoClasses functionality we can reuse the code on a large number of transformers models!
This notebook is designed to:
- Use an already pretrained transformers model and fine-tune (continue training) it on your custom dataset.
- Train a transformer model from scratch on a custom dataset. This requires an already trained (pretrained) tokenizer. This notebook will use by default the pretrained tokenizer if an already trained tokenizer is no provided.
This notebook is heavily inspired from the Hugging Face script used for training language models: transformers/tree/master/examples/language-modeling. I basically adapted that script to work nicely in a notebook with a lot more comments.
Notes from transformers/tree/master/examples/language-modeling: Fine-tuning the library models for language modeling on a text file (GPT, GPT-2, CTRL, BERT, RoBERTa, XLNet). GPT, GPT-2 and CTRL are fine-tuned using a causal language modeling (CLM) loss. BERT and RoBERTa are fine-tuned using a masked language modeling (MLM) loss. XLNet is fine-tuned using a permutation language modeling (PLM) loss.
What should I know for this notebook?
Since I am using PyTorch to fine-tune our transformers models any knowledge on PyTorch is very useful.
Knowing a little bit about the transformers library helps too.
In this notebook I am using raw text data to pretrain / train / fine-tune transformers models . There is no need for labeled data since we are not doing classification. The Transformers library handles the text files in same way as the original implementation of each model did.
How to use this notebook?
Like with every project, I built this notebook with reusability in mind. This notebook uses a custom dataset from.txt files. Since the dataset does not come in a single .txt file I created a custom function movie_reviews_to_file that reads the dataset and creates the text file. The way I load the .txt files can be easily reused for any other dataset.
The only modifications needed to use your own dataset will be in the paths provided to the train .txt file and evaluation .txt file.
All parameters that need to be changed are under the Parameters Setup section. Each parameter is nicely commented and structured to be as intuitive as possible.
What transformers models work with this notebook?
A lot of people will probably use it for Bert. When there is a need to run a different transformer model architecture, which one would work with this code? Since the name of the notebooks is pretrain_transformers it should work with more than one type of transformers.
I ran this notebook across all the pretrained models found on Hugging Face Transformer. This way you know ahead of time if the model you plan to use works with this code without any modifications.
The list of pretrained transformers models that work with this notebook can be found here. There are 67 models that worked 😄 and 39 models that failed to work 😢 with this notebook. Remember these are pretrained models and fine-tuned on custom dataset.
Dataset
This notebook will cover pretraining transformers on a custom dataset. I will use the well known movies reviews positive — negative labeled Large Movie Review Dataset.
The description provided on the Stanford website:
This is a dataset for binary sentiment classification containing substantially more data than previous benchmark datasets. We provide a set of 25,000 highly polar movie reviews for training, and 25,000 for testing. There is additional unlabeled data for use as well. Raw text and already processed bag of words formats are provided. See the README file contained in the release for more details.
Why this dataset? I believe is an easy to understand and use dataset for classification. I think sentiment data is always fun to work with.
Coding
Now let’s do some coding! We will go through each coding cell in the notebook and describe what it does, what’s the code, and when is relevant — show the output.
I made this format to be easy to follow if you decide to run each code cell in your own python notebook.
When I learn from a tutorial I always try to replicate the results. I believe it’s easy to follow along if you have the code next to the explanations.
Downloads
Download the Large Movie Review Dataset and unzip it locally.
Installs
- transformers library needs to be installed to use all the awesome code from Hugging Face. To get the latest version I will install it straight from GitHub.
- ml_things library used for various machine learning related tasks. I created this library to reduce the amount of code I need to write for each machine learning project.
Imports
Import all needed libraries for this notebook.
Declare basic parameters used for this notebook:
set_seed(123)- Always good to set a fixed seed for reproducibility.device- Look for gpu to use. I will use cpu by default if no gpu found.
Helper Functions
I like to keep all Classes and functions that will be used in this notebook under this section to help maintain a clean look of the notebook:
movie_reviews_to_file(path_data: str, path_texts_file: str)
As I mentioned before, we will need .txt files to run this notebook. Since the Large Movie Review Dataset comes in multiple files with different labels I created this function to put together all data in a single .txt file. Examples are saved on each line of the file. The path_data points to the path where data files are present and path_texts_file will be the .txt file containing all data.
ModelDataArguments
This class follows similar format as the transformers library. The main difference is the way I combined multiple types of arguments into one and used rules to make sure the arguments used are correctly set. Here are all argument detailed (they are also mentioned in the class documentation):
train_data_file: Path to your.txtfile dataset. If you have an example on each line of the file make sure to useline_by_line=True. If the data file contains all text data without any special grouping useline_by_line=Falseto move ablock_sizewindow across the text file.eval_data_file: Path to evaluation.txtfile. It has the same format astrain_data_file.line_by_line: If thetrain_data_fileandeval_data_filecontains separate examples on each line setline_by_line=True. If there is no separation between examples andtrain_data_fileandeval_data_filecontains continuous text thenline_by_line=Falseand a window ofblock_sizewill be moved across the files to acquire examples.mlm: Is a flag that changes loss function depending on model architecture. This variable needs to be set toTruewhen working with masked language models like bert or roberta and set toFalseotherwise. There are functions that will raise ValueError if this argument is not set accordingly.whole_word_mask: Used as flag to determine if we decide to use whole word masking or not. Whole word masking means that whole words will be masked during training instead of tokens which can be chunks of words.mlm_probability: Used when training masked language models. Needs to havemlm=True. It represents the probability of masking tokens when training model.plm_probability: Flag to define the ratio of length of a span of masked tokens to surrounding context length for permutation language modeling. Used for XLNet.max_span_length: Flag may also be used to limit the length of a span of masked tokens used for permutation language modeling. Used for XLNet.block_size: It refers to the windows size that is moved across the text file. Set to -1 to use maximum allowed length.overwrite_cache: If there are any cached files, overwrite them.model_type: Type of model used: bert, roberta, gpt2. More details here.model_config_name: Config of model used: bert, roberta, gpt2. More details here.tokenizer_name: Tokenizer used to process data for training the model. It usually has same name asmodel_name_or_path: bert-base-cased, roberta-base, gpt2 etc.model_name_or_path: Path to existing transformers model or name of transformer model to be used: bert-base-cased, roberta-base, gpt2 etc. More details here.model_cache_dir: Path to cache files. It helps to save time when re-running code.
get_model_config(args: ModelDataArguments)
Get model configuration. Using the ModelDataArguments to return the model configuration. Here are all argument detailed:
args: Model and data configuration arguments needed to perform pretraining.- Returns: Model transformers configuration.
- Raises: ValueError: If
mlm=Trueandmodel_typeis NOT in ["bert", "roberta", "distilbert", "camembert"]. We need to use a masked language model in order to setmlm=True.
get_tokenizer(args: ModelDataArguments)
Get model tokenizer.Using the ModelDataArguments return the model tokenizer and change block_size form args if needed. Here are all argument detailed:
args: Model and data configuration arugments needed to perform pretraining.- Returns: Model transformers tokenizer.
get_model(args: ModelDataArguments, model_config)
Get model. Using the ModelDataArguments return the actual model. Here are all argument detailed:
args: Model and data configuration arguments needed to perform pretraining.model_config: Model transformers configuration.- Returns: PyTorch model.
get_dataset(args: ModelDataArguments, tokenizer: PreTrainedTokenizer, evaluate: bool=False)
Process dataset file into PyTorch Dataset. Using the ModelDataArguments return the actual model. Here are all argument detailed:
args: Model and data configuration arguments needed to perform pretraining.tokenizer: Model transformers tokenizer.evaluate: If set toTruethe test / validation file is being handled. If set toFalsethe train file is being handled.- Returns: PyTorch Dataset that contains file’s data.
get_collator(args: ModelDataArguments, model_config: PretrainedConfig, tokenizer: PreTrainedTokenizer)
Get appropriate collator function. Collator function will be used to collate a PyTorch Dataset object. Here are all argument detailed:
args: Model and data configuration arguments needed to perform pretraining.model_config: Model transformers configuration.tokenizer: Model transformers tokenizer.- Returns: Transformers specific data collator.
Parameters Setup
Declare the rest of the parameters used for this notebook:
model_data_argscontains all arguments needed to setup dataset, model configuration, model tokenizer and the actual model. This is created using theModelDataArgumentsclass.training_argscontain all arguments needed to use the Trainer functionality from Transformers that allows us to train transformers models in PyTorch very easy. You can find the complete documentation here. There are a lot of parameters that can be set to allow multiple functionalities. I only used the following parameters (the comments are inspired from the HuggingFace documentation of TrainingArguments:output_dir: The output directory where the model predictions and checkpoints will be written. I set it up topretrained_bert_modelwhere the model and will be saved.overwrite_output_dir: Overwrite the content of the output directory. I set it toTruein case I run the notebook multiple times I only care about the last run.do_train: Whether to run training or not. I set this parameter toTruebecause I want to train the model on my custom dataset.do_eval: Whether to run evaluation on the evaluation files or not. I set it toTruesince I have test data file and I want to evaluate how well the model trains.per_device_train_batch_size: Batch size GPU/TPU core/CPU training. I set it to2for this example. I recommend setting it up as high as your GPU memory allows you.per_device_eval_batch_size: Batch size GPU/TPU core/CPU for evaluation.I set this value to100since it's not dealing with gradients.evaluation_strategy: Evaluation strategy to adopt during training:no: No evaluation during training;steps: Evaluate everyeval_steps;epoch`: Evaluate every end of epoch. I set it to 'steps' since I want to evaluate model more often.logging_steps: How often to show logs. I will se this to plot history loss and calculate perplexity. I set this to20just as an example. If your evaluate data is large you might not want to run it that often because it will significantly slow down training time.eval_steps: Number of update steps between two evaluations if evaluation_strategy="steps". Will default to the same value as logging_steps if not set. Since I want to evaluate model everlogging_stepsI will set this toNonesince it will inherit same value aslogging_steps.prediction_loss_only: Set prediction loss toTruein order to return loss for perplexity calculation. Since I want to calculate perplexity I set this toTruesince I want to monitor loss and perplexity (which is exp(loss)).learning_rate: The initial learning rate for Adam. Defaults is set to5e-5.weight_decay: The weight decay to apply (if not zero)Defaults is set to0.adam_epsilon: Epsilon for the Adam optimizer. Defaults to1e-8.max_grad_norm: Maximum gradient norm (for gradient clipping). Defaults to0.num_train_epochs: Total number of training epochs to perform (if not an integer, will perform the decimal part percents of the last epoch before stopping training). I set it to2at most. Since the custom dataset will be a lot smaller than the original dataset the model was trained on we don't want to overfit.save_steps: Number of updates steps before two checkpoint saves. Defaults to500.
Load Configuration, Tokenizer and Model
Loading the three essential parts of the pretrained transformers: configuration, tokenizer and model.
Since I use the AutoClass functionality from Hugging Face I only need to worry about the model’s name as input and the rest is handled by the transformers library.
I will be calling each three functions created in the Helper Functions tab that help return config of the model, tokenizer of the model and the actual PyTorch model.
After model is loaded is always good practice to resize the model depending on the tokenizer size. This means that the tokenizer's vocabulary will be aligned with the models embedding layer. This is very useful when we have a different tokenizer that the pretrained one or we train a transformer model from scratch.
Loading model configuration...
Downloading: 100%|████████████████████████████████|433/433 [00:01<00:00, 285B/s] Loading model`s tokenizer...
Downloading: 100%|████████████████████████████████|433/433 [00:01<00:00, 285B/s] Loading actual model...
Downloading: 100% |████████████████████████████████|436M/436M [00:36<00:00, 11.9MB/s] Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForMaskedLM: ['cls.seq_relationship.weight', 'cls.seq_relationship.bias'] - This IS expected if you are initializing BertForMaskedLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPretraining model). - This IS NOT expected if you are initializing BertForMaskedLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Embedding(28996, 768, padding_idx=0)
Dataset and Collator
This is where I create the PyTorch Dataset and data collator objects that will be used to feed data into our model.
This is where I use the MovieReviewsDataset text files created with the movie_reviews_to_file function. Since data is partitioned for both train and test I will create two text files: one used for train and one used for evaluation.
I strongly recommend to use a validation text file in order to determine how much training is needed in order to avoid overfitting. After you figure out what parameters yield the best results, the validation file can be incorporated in train and run a final train with the whole dataset.
The data collator is used to format the PyTorch Dataset outputs to match the output of our specific transformers model: i.e. for Bert it will created the masked tokens needed to train.
Reading `train` partition... neg: 100%|████████████████████████████████|12500/12500 [00:55<00:00, 224.11files/s] pos: 100%|████████████████████████████████|12500/12500 [00:55<00:00, 224.11files/s] `.txt` file saved in `/content/train.txt` Reading `test` partition... neg: 100%|████████████████████████████████|12500/12500 [00:55<00:00, 224.11files/s] pos: 100%|████████████████████████████████|12500/12500 [00:55<00:00, 224.11files/s] `.txt` file saved in `/content/train.txt` Creating train dataset... Creating evaluate dataset...Train
Hugging Face was very nice to us for creating the Trainer class. This helps make PyTorch model training of transformers very easy! We just need to make sure we loaded the proper parameters and everything else is taking care of!
At the end of the training the tokenizer is saved along with the model so you can easily re-use it later or even load in on Hugging Face Models.
I configured the arguments to display both train and validation loss at every logging_steps. It gives us a sense of how well the model is trained.
Loading `trainer`...
Start training... |████████████████████████████████|[5000/5000 09:43, Epoch 2/2]
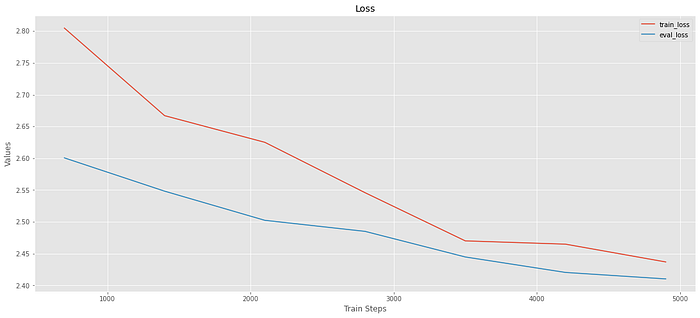
Step Training Loss Validation Loss
700 2.804672 2.600590
1400 2.666996 2.548267
2100 2.625075 2.502431
2800 2.545872 2.485056
3500 2.470102 2.444808
4200 2.464950 2.420487
4900 2.436973 2.410310Plot Train
The Trainer class is so useful that it will record the log history for us. I use this to access the train and validation losses recorded at each logging_steps during training.
Since we are training / fine-tuning / extended training or pretraining (depending what terminology you use) a language model, we want to compute the perplexity.
This is what Wikipedia says about perplexity: In information theory, perplexity is a measurement of how well a probability distribution or probability model predicts a sample. It may be used to compare probability models. A low perplexity indicates the probability distribution is good at predicting the sample.
We can look at the perplexity plot in the same way we look at the loss plot: the lower the better and if the validation perplexity starts to increase we are starting to overfit the model.
Note: It looks from the plots that the train loss is higher than validation loss. That means that our validation data is too easy for the model and we should use a different validation dataset. Since the purpose of this notebook is to show how to train transformers models and provide tools to evaluate such process I will leave the results as is.

Evaluate
For the final evaluation we can have a separate test set that we use to do our final perplexity evaluation. For simplicity I used the same validation text file for the final evaluation. That is the reason I get the same results as the last validation perplexity plot value.
|████████████████████████████████|[250/250 00:25] Evaluate Perplexity: 11.01Final Note
If you made it this far Congrats! 🎊 and Thank you! 🙏 for your interest in my tutorial!
I’ve been using this code for a while now and I feel it got to a point where is nicely documented and easy to follow.
Of course is easy for me to follow because I built it. That is why any feedback is welcome and it helps me improve my future tutorials!
If you see something wrong please let me know by opening an issue on my ml_things GitHub repository!
A lot of tutorials out there are mostly a one-time thing and are not being maintained. I plan on keeping my tutorials up to date as much as I can.
Contact
🦊 GitHub: gmihaila
🌐 Website: gmihaila.github.io
👔 LinkedIn: mihailageorge
📬 Email: georgemihaila@my.unt.edu.com
Originally published at https://gmihaila.github.io.
